Jailbreaking LLMs
Jailbreaking LLMs is best understood as a robustness problem, not as a list of magic prompts. Safety-trained language models have to satisfy multiple objectives at once: follow the user's instruction, obey higher-priority policy, preserve helpfulness, and continue the conversation in natural language. Research on safety-training failures describes two recurring causes: competing objectives and mismatched generalization between training examples and new adversarial inputs (Jailbroken). That framing is more useful than treating jailbreaks as clever phrasing. It explains why the problem keeps returning after any single pattern gets patched.
The Mechanical Problem
An autoregressive model does not apply a symbolic rulebook at generation time. It predicts the next token from the prompt, system context, training distribution, and any decoding constraints. Safety training changes the model's behavior, but the model still has to generalize from finite training data to inputs no one enumerated in advance (Jailbroken).
That creates a hard boundary for defense design. A direct harmful request may fall into a well-trained refusal region. A rewritten request, a multi-step framing, or a long-context demonstration can land somewhere else. The model may still "know" the policy target, but the local prompt evidence can pull the generation toward instruction-following behavior. The safety issue is not that one phrase beats one rule. The issue is that natural language gives the attacker a huge surface for changing how the model interprets the task.
Competing Objectives
The Jailbroken paper argues that many failures come from two pressures pulling in different directions. The model has been trained to be helpful and instruction-following, and it has also been trained to refuse some classes of request (Jailbroken). When a prompt makes the unsafe part indirect, hypothetical, translated, role-framed, or embedded in another task, those objectives can conflict.
Architecture consequence: if you rely on one aligned decoder to both parse intent and enforce safety, you have coupled two jobs that sometimes disagree. Safer systems add layers around the model: classifiers, retrieval constraints, tool permissions, audit logs, and deterministic policy checks. Those layers do not make the language model perfectly robust, but they stop one generation step from becoming the only control point.
Automated Attacks
Modern jailbreaks are not limited to human-written roleplay. Zou et al. showed that adversarial suffixes can be optimized automatically and can transfer to public black-box models (Universal and transferable adversarial attacks). That result changed the threat model. A defender cannot assume that attack prompts will look like normal prose or that filtering known strings will cover the space.
The mechanism is brittleness. If a suffix exploits a narrow region of the model's learned behavior, small perturbations may break it. SmoothLLM uses that observation by randomly perturbing prompts and checking whether model behavior remains stable, reporting robustness gains with a utility trade-off (SmoothLLM). This defense treats jailbreaks as fragile adversarial inputs, not semantic requests alone.
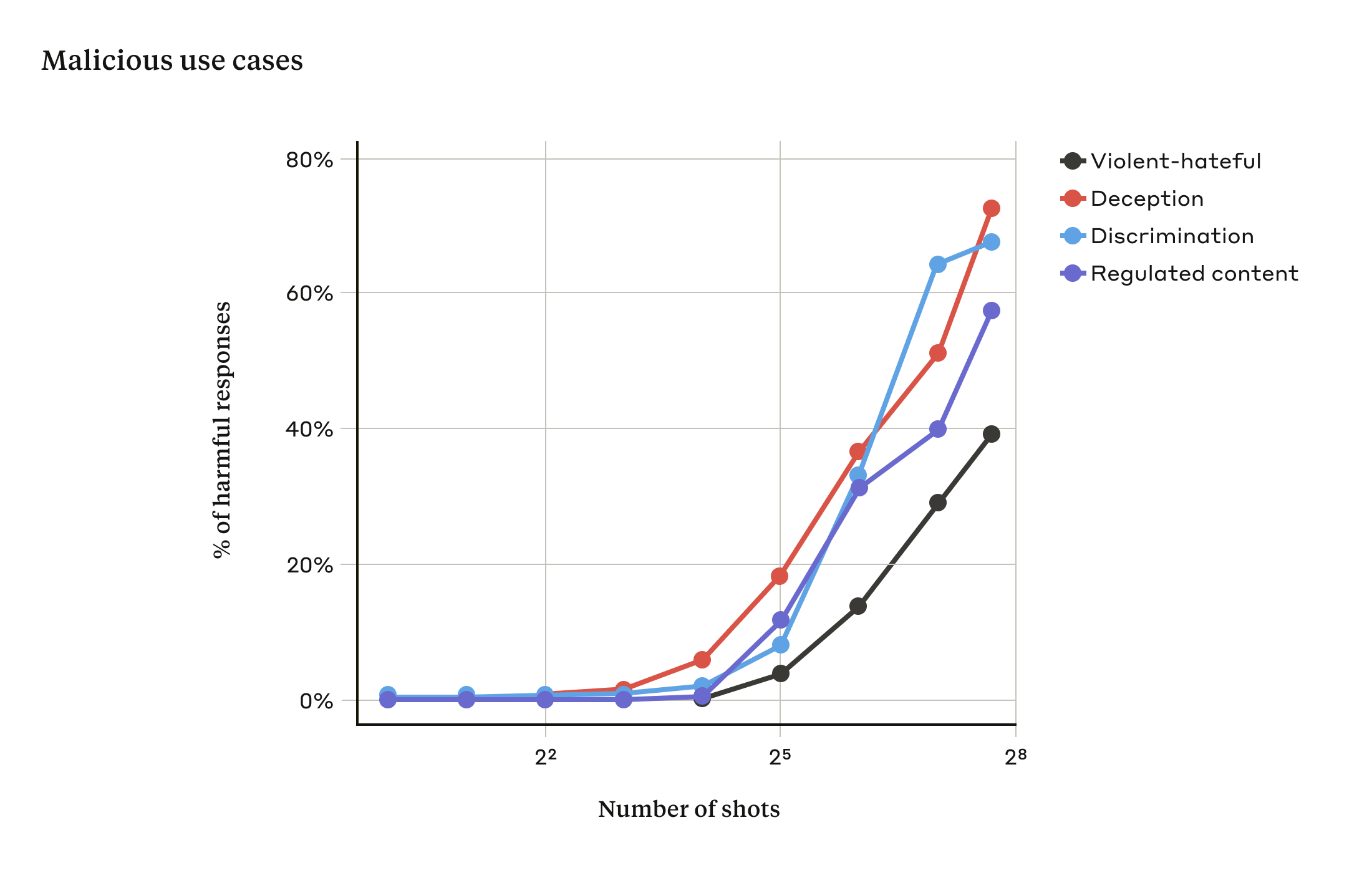
Long Context
Long context opens another path. Anthropic's many-shot jailbreaking work shows that a prompt containing many examples of unsafe compliance can use in-context learning to pull a model toward similar behavior later in the same context (Many-shot jailbreaking). This is architecturally awkward because the same feature that makes long-context models useful, learning patterns from examples in the prompt, also gives an attacker more room to demonstrate the behavior they want.
Do not reduce this to "shorten every context window." Safety has to account for the full context, not only the final user turn. If retrieval, chat history, documents, or tool outputs enter the context, they become part of the instruction surface. A long context window is memory, but it is also attack area.
Prompt Injection and Tools
Prompt injection becomes sharper once the model can use tools. The UK National Cyber Security Centre argues that prompt injection is not analogous to SQL injection because an LLM cannot reliably separate instructions from data when both arrive as natural language (NCSC prompt-injection note). OpenAI's Model Spec formalizes an instruction hierarchy, but hierarchy is not isolation: the model still has to interpret natural-language instructions and data inside one context (OpenAI Model Spec). The model is an "inherently confusable deputy": it receives text, interprets text, and may take actions based on text.
That changes how you should build agents. Do not ask the model to be the only boundary between untrusted data and privileged actions. Use typed tool schemas, permission checks, allowlists, scoped credentials, and separate policy logic. A model can reason about a request, but deterministic code should decide whether a high-impact action is allowed.
Defense Stack
No single defense owns the whole problem. RLHF and refusal fine-tuning change the model's default behavior. Input and output classifiers add an independent check. Prompt perturbation methods probe brittle attacks. Rapid-response pipelines update defenses after a new attack appears. Anthropic's Constitutional Classifiers report reduced jailbreak success from 86% to under 5% in their evaluation, with a 0.38% increase in harmless-query refusals and about 23.7% extra compute (Constitutional Classifiers).
Those numbers show the trade-off. Stronger filters cost compute and can refuse benign requests. Weaker filters preserve utility but leave more attack surface. The Rapid Response work makes a pragmatic point: because perfect robustness is unrealistic, defenders need fast adaptation once a jailbreak class is discovered (Rapid Response).
| Layer | What it helps with | What still leaks |
|---|---|---|
| Safety training | Moves default behavior toward refusal on known risky patterns | Mismatched generalization on new framings |
| Classifiers | Adds an independent policy check before or after generation | False positives, false negatives, extra latency |
| Prompt perturbation | Catches brittle adversarial suffixes | Semantic attacks that remain stable under perturbation |
| Tool permissions | Prevents text-only confusion from becoming privileged action | Bad policy design or overbroad credentials |
| Rapid response | Shrinks exposure after a new attack appears | First-wave failures before the patch |
The Testing Impulse
My interpretation: people probe models because polished behavior hides the boundary between capability and policy. A refusal tells you that a system chose not to answer, but it does not tell you whether the model lacks the knowledge, whether a classifier blocked the request, or whether the prompt landed in a safety-trained region. That opacity invites testing.
Curiosity is not a license to seek harmful output. It is a reason to build better evaluations. The useful version of the jailbreak impulse is red-team discipline: isolate failure modes, avoid publishing operational attack recipes, measure the defense, and route findings back into the system.
Takeaways
Jailbreaking persists because safety-trained LLMs generalize from finite examples over a huge natural-language input space. The strongest explanations point to competing objectives, mismatched generalization, automated adversarial suffixes, long-context in-context learning, and tool-use confusion. The engineering answer is layered defense: train safer defaults, classify risky inputs and outputs, constrain tools with deterministic permissions, and update defenses quickly after new attack classes appear. The model should participate in safety reasoning, but it should not be the only safety boundary.
References
- Wei et al., "Jailbroken: How Does LLM Safety Training Fail?"
- Ouyang et al., "Training language models to follow instructions with human feedback"
- Bai et al., "Constitutional AI: Harmlessness from AI Feedback"
- Zou et al., "Universal and Transferable Adversarial Attacks on Aligned Language Models"
- Anthropic, "Many-shot jailbreaking"
- Robey et al., "SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks"
- UK NCSC, "Prompt injection is not SQL injection"
- OpenAI Model Spec
- Anthropic, "Constitutional Classifiers: Defending against universal jailbreaks"
- Rapid Response: Mitigating LLM Jailbreaks with a Few Examples
author: Ope tag: #ai links: [[Three Layers — Tool, MCP, Skill]], [[Small LLMs — Use Cases and Limits]], [[Multi-Token Prediction]]
